On Computer Vision
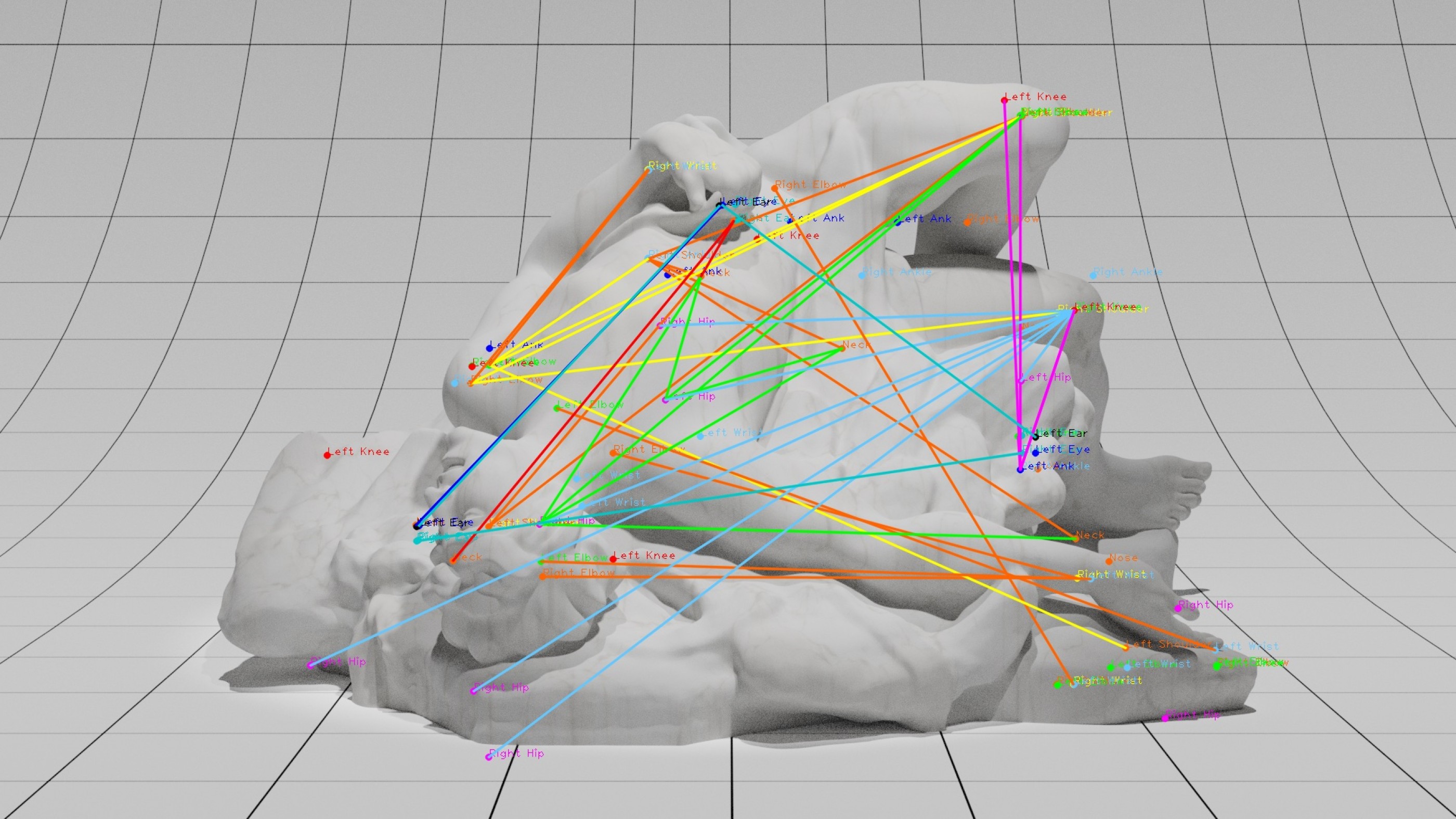
Figure 1: The Fall of Icarus with human pose detection keypoints. © Adam Harvey 2021. Based on a 3D model by Scan the World.
Photography has become a nineteenth-century way of looking at a twenty-first-century world. In its place emerged a new optical regime: computer vision.
Computer vision changes how people see the world. It mediates the relationship between input and output, abstracting reality through algorithmic transformations. Computer vision acts as optical middleware, intercepting reality and projecting objectivity through an inherited interface of truth. Computer vision, unlike photography, does not mirror reality but instead interprets and misinterprets it, overlaying statistical assumptions of meaning. There is no truth in the output of computer vision algorithms, only statistical probabilities clipped into Boolean states masquerading as truthy outcomes with meaning added in post-production.
Face detection algorithms, for example, do not actually detect faces, though they claim to. Face detection merely detects face-like regions, assigning each with a confidence score. Ultimately, a developer or administrator decides how much a facial region should be considered a real face in order to qualify as such. Setting the threshold is the final decision that connects the algorithmic world to the human world, each with their own biases. Thresholds are subjective and contextual. Face detection systems used in security applications will have different threshold parameters than face detection used in consumer applications. This implies that the definition and boundaries of a face are dynamic and defined by environmental constraints. For a face detection system to find all faces in an image, the threshold can be lowered—but this causes false positives. To remove false positives the threshold is increased—but this causes more false negatives. Detecting faces means finding harmony between false positives, false negatives, true positives, and true negatives. In face detection systems, faces are probabilistic objects, eventually reduced to a single Boolean variable: face or no face, true or false.
If the thresholds are incorrectly set or tampered with, face detection can fail hysterically. In Fig. 2, a single shot detector (SSD) face detection algorithm proposed hundreds of face-like regions when the thresholds were set too low. The over-confidence exposes the neural network’s naïveté and shows that face detection is never absolute, but always a probabilistic determination.

Figure 2: Face detection with 0% thresholding using a Single Shot Detector (SSD) face detection neural network. There is no truth face detection, only probabilities and thresholds. Created using VFRAME computer vision toolkit. Image: © Adam Harvey 2021
Algorithms are rule sets, and these rules are limited by the perceptual capacities of sensing technologies. This creates “perceptual topologies”[1] that reflect how technology can or cannot see the world. In the first widely used face detection algorithm, developed in 2001 by Viola and Jones,[2] the definition of a face relied on the available imagery of the time for training data. This comprised blurry, low resolution, grayscale CCTV imagery. The Viola-Jones face detection algorithm mirrored back the perceptual biases of low-resolution CCTV systems from the early 2000s by encoding a blurry, noisy, grayscale definition of the human face. Understanding this perceptual topology can also help discover perceptual vulnerabilities. In my research for CV Dazzle[3] (2010) and HyperFace (2016) I showed that the Viola-Jones Haar Cascade algorithm is vulnerable to presentation attacks using low-cost makeup and hair hacks that obscure the expected low resolution face features, primarily the nose-bridge area. By simply inverting the blocky features of their Haar Cascade algorithm with long hair or bold makeup patterns, faces could effectively disappear from security systems. Another vulnerability of the Haar Cascade algorithm is its reliance on open-source face detection profiles, which can be reverse-engineered to produce the most face-like face. In 2016, I exploited this vulnerability for the HyperFace[4] project to fool (now outdated) face detection systems into thinking dozens of human faces existed in a pink, pixellated graphic on a fashion accessory (Fig. 3).

Figure 3: The HyperFace pattern, developed in 2016, deceives the Viola-Jones haarcascade face detection algorithm by presenting the most face-like shapes. Image: Copyright ©Adam Harvey
When we see the world through computer vision systems, we begin to see the flaws and limitations of a world mediated by algorithms, data, and sensors. Whereas photographers initially saw the world warped through their own camera’s viewfinder system, or flattened into a silver-gelatin print, the computer vision operator sees a world twisted by algorithms which in turn reflect a world constructed from warped and biased training datasets.
Training datasets are the lifeblood of artificial intelligence. They are so vital to the way computer vision models understand visual input that it may be helpful to reconsider the algorithms as data-driven code, reflecting a broader trend in computational thinking to reimagine the concept of programming altogether. Geoffrey Hinton, a progenitor of modern day deep learning, thinks that “our relationship to computers has changed… Instead of programming them, we now show them and they figure it out.”[5] Meanwhile the AI expert Kai-Fu Lee says “AI is basically run on data.” The new logic is not better algorithms, but more data. “The more data the better the AI works, more brilliantly than how the researcher is working on the problem.”[6] And according to Chris Darby, CEO and president of CIA’s In-Q-Tel group, “an algorithm without data is useless.”[7] In other words, the extent to which a computer vision algorithm can interpret the world is limited, guided, and programmed by image training datasets. Seeing with computer vision is seeing through the lens of training data. Light is no longer interpreted as a direct impression of electromagnetic energy in the optical spectrum, but also as the weights and biases of an archive’s afterglow.
When computer vision algorithms are trained on image datasets, they learn to associate each object in an image with a class or label. This type of supervised learning is subjective and based on existing taxonomies that often inherit outdated and problematic ways of thinking. To paraphrase the artist Trevor Paglen, whoever controls the dataset controls the meaning. In Paglen’s ImageNet Roulette[8] he excavates the flawed taxonomies that persisted in the WordNet labeling system that was used to label ImageNet, then purposefully trained a flawed image classification algorithm to demonstrate the dangers of racist and misogynistic classification structures. The dataset was eventually reformed by its creators at Stanford to “correct” the labels. But this leads to further questions: is it ever fair to automatically impose taxonomies using biometric facial data obtained without consent? Would it be better to not be classified at all? Or should we demand classification with representation? Is this even a real choice we get to make? An essay by Google researcher Dr. Alex Hanna points out that solving representational problems in image training datasets is not necessarily a move in the right direction, writing that when blaming algorithmic bias problems on “underrepresentation of a marginalized population within a dataset, solutions are subsumed to a logic of accumulation; the underlying presumption being that larger and more diverse datasets will eventually morph into (mythical) unbiased datasets.”[9] In no small way it is photography, photographers, and the photographs of the past that inform and haunt the ways computer vision interprets and misinterprets the world today and into the future.
Photographers have a new and important role to play today in shaping the datasets that shape algorithms, which in turn reflect how we see the world and each other. Photographers, as one of the primary visual data creators, can affect the way people see the world by changing the way computers see the world because we now see the world through computers, and computers in turn see the world through us. Without data, algorithms are indeed useless.
We, as data subjects, also have a role to play. Whether or not we consented to our faces and bodies appearing in photos, many go on to become training data. In research for the Exposing.ai project, it has been shown that millions of images appearing on Flickr and other social media sharing sites have been used in facial recognition training datasets. One dataset, called MegaFace, collected over 4 million faces from Flickr which were then used in dozens of defense and security related applications including by US defense contractor Northrop Grumman; In-Q-Tel, the investment arm of the Central Intelligence Agency; ByteDance, the parent company of the Chinese social media app TikTok; the Chinese surveillance company Megvii; the European Law Enforcement Agency (Europol), Facebook, Google, Hikvision, Huawei, IARPA, and Microsoft, to name only a few among thousands more.
Becoming training data is political, especially when that data is biometric. But resistance to militarised face recognition and citywide mass surveillance can only happen at a collective level. At a personal level, the dynamics and attacks that were once possible to defeat the Viola-Jones Haar Cascade algorithm are no longer relevant. Neural networks are anti-fragile. Attacking makes them stronger. So-called adversarial attacks are rarely adversarial in nature. Most often they are used to fortify a neural network. In the new optical regime of computer vision every image is a weight, every face is a bias, and every body is a commodity in a global information supply chain.
[1] Fabian Offert and Peter Bell, “Perceptual Bias and Technical Metapictures: Critical Machine Vision as a Humanities Challenge,” AI and Society (October 12, 2020), https://doi.org/10.1007/s00146-020-01058-z.
[2] “Viola–Jones Object Detection Framework,” Wikipedia, https://en.wikipedia.org/wiki/Viola%E2%80%93Jones_object_detection_framework, accessed December 6, 2021.
[4] https://ahprojects.com/hyperface.
[5] “Heroes of Deep Learning: Andrew Ng Interviews Geoffrey Hinton,” YouTube, August 8, 2017, https://www.youtube.com/watch?v=-eyhCTvrEtE, accessed December 6, 2021.
[6] “In the Age of AI,” Frontline, podcast, November 14, 2019, https://podcasts.apple.com/de/podcast/frontlinefilm-audio-track-pbs/id336934080?l=en&i=1000456779283, accessed December 6, 2021.
[7] “In-Q-Tel President Chris Darby on Investment and Innovation in U.S. Intelligence Matters,” Intelligence Matters, podcast, April 23, 2019, https://podcasts.apple.com/us/podcast/inq-tel-president-chris-darby-on-investment-innovation/id1286906615?i=1000436184139, accessed December 6, 2021.
[8] Trevor Paglen. 2019. https://imagenet-roulette.paglen.com
[9] Alex Hanna, et al., “Lines of Sight,” Logic Mag, vol. 12 (2020), https://logicmag.io/commons/lines-of-sight/, accessed December 6, 2021.
Subscribe to our newsletter!
By subscribing you agree to the terms and conditions.
We will not send any advertisements.
About the author
Published on 2021-12-08 20:21